
How I Finally Understood Supervised Fine-Tuning vs. RLHF (and Why It Changed How I See AI)
From Architect's Desk

Why does ChatGPT feel like it understands me?”
This was a question I asked myself when I first started digging deeper into how AI assistants actually learn to be so good at conversations, explanations, and even creativity.
I already knew about pre-training ,the part where a model is fed a ton of internet data and learns how to predict the next word.
But that wasn’t enough to explain the magic.
So I kept going.
And that’s when I found out about two concepts that completely changed how I see modern AI systems:
Supervised Fine-Tuning (SFT)
Reinforcement Learning from Human Feedback (RLHF)
Let me walk you through what I learned in plain English with examples, strategies, and real use cases. I promise, by the end of this post, you’ll understand how smart assistants are really made.
Let's Start at the Top: What Happens After Pre-training?
If pre-training makes a model "language-literate," the next stages are what make it a helpful assistant.
Here’s the typical training journey of an LLM:
1. Pre-training → 2. Supervised Fine-Tuning → 3. RLHF
Each step adds a new layer of intelligence and alignment.
Supervised Fine-Tuning (SFT): Teaching the Model with Flashcards
The first step after pre-training is Supervised Fine-Tuning.
I like to think of it like this:
You're giving the model a series of questions and exactly the answer it should give.
The model’s job is to learn: “When I see this, I should say that.”
Real Example I Worked With:
Prompt: “What’s the difference between an S-corp and C-corp?”
Ideal Output: “An S-corp is a pass-through entity taxed once, while a C-corp is taxed at both corporate and shareholder levels…”
The model gets hundreds of thousands of these pairs across topics programming, law, biology, even email writing and learns patterns.
Behind the Scenes:
It uses cross-entropy loss (basically measuring how far off it is from the right answer).
Optimized with Adam or similar optimizers.
Happens on multi-GPU setups using frameworks like Hugging Face’s
transformers.
This phase teaches the model how to follow instructions, stick to formats (like JSON or Markdown), and avoid hallucinating too early.
RLHF: Giving the Model Human-Like Judgment
But here’s the thing
Even after SFT, the model still doesn’t know which answer is better. It just knows how to mimic training data.
That’s where Reinforcement Learning from Human Feedback (RLHF) comes in and it blew my mind.
Instead of training the model to match a single correct answer, we train it to choose the best answer from a few options based on what humans prefer.
The Flow Looks Like This:
Start with an SFT-trained model.
Ask humans to rank outputs for a prompt.
Train a reward model to predict those rankings.
Use reinforcement learning (usually PPO) to fine-tune the base model so it maximizes the reward score.
It’s not just: “Is this right?”
It’s: “Would a person like this response more?”
Story Example:
I remember trying this in a project where we asked labellers to rank LLM-generated answers to beginner coding questions.
Some answers were technically correct but cold and robotic.
Others used analogies, simple language, and were more “human.”
Humans picked the second every time.
The model learned that tone and approach matter.
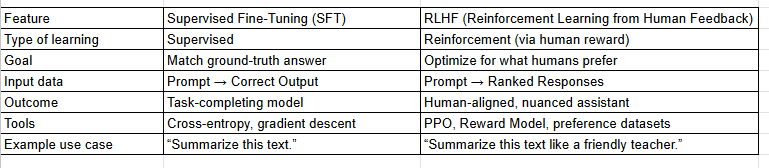
SFT vs. RLHF: Side-by-Side
How This Works at Scale
When you’re working with millions of examples and huge models, training becomes a systems problem too.
How SFT Is Scaled:
Use synthetic data (generated completions + human filtering)
Curriculum learning (start with simpler tasks)
Mix of public datasets + expert answers
How RLHF Is Scaled:
Use model-assisted feedback collection
Hire domain experts for harder evaluations
Sometimes use DPO (Direct Preference Optimization) to skip PPO training
What Surprised Me the Most
SFT felt straightforward to me it’s supervised learning 101.
But RLHF changed the game. It helped me see AI training as more of a dialogue with humans. The system doesn’t just learn what to say it learns how to say it well.
And that made me realize…
Alignment isn’t just technical it’s emotional, behavioural, even cultural.
That’s why systems like ChatGPT, Claude, and Gemini feel more thoughtful—they’ve been shaped by people. Not just coders, but teachers, writers, designers, and ethicists.
TL;DR — The Big Idea
Supervised Fine-Tuning (SFT) teaches how to complete tasks.
RLHF teaches how to align outputs with human values.
Together, they’re how today’s models evolve from knowledge bases to assistants.
Want to Learn Hands-On?
If this made you curious, I recommend starting with open-source experiments using:
trlfrom Hugging Face for RLHFpeftfor low-rank adapters (cheaper fine-tuning)text-davinci-003or Llama-style models for hands-on SFT trials
And if you're curious, I’d be happy to drop a Collab notebook or GitHub repo to get you started. Just reply or comment.
Thanks for learning with me.
If this kind of breakdown helped you, consider subscribing and sharing with a friend. Next week, I’ll break down how Direct Preference Optimization (DPO) is changing the game by simplifying the RLHF pipeline.